

Google has released a new optimization layer for its Gemma 4 family, aiming to address one of the most persistent limitations in modern AI systems: inference latency. The update introduces Multi-Token Prediction (MTP) drafters, a method built on speculative decoding that can accelerate text generation by up to three times without reducing output quality or reasoning performance.
The release follows the recent debut of Gemma 4, which recorded more than 60 million downloads within weeks, according to the company. With MTP drafters, Google shifts focus from model capability to execution efficiency, a constraint that developers often encounter when deploying AI systems on real hardware.
Gemma 4: Now up to 3x Faster. ⚡
— Google for Developers (@googledevs) May 5, 2026
Same quality, way more speed. Our new MTP drafters allow Gemma 4 to predict multiple tokens at once, effectively tripling your output speed without compromising intelligence. pic.twitter.com/xyltPFFVMw
The bottleneck behind modern AI systems
Running large language models on local machines often exposes a gap between theoretical performance and practical usability. Standard models generate text one token at a time, and each token requires moving vast amounts of data between memory and compute units. This process creates delays that become especially noticeable on consumer-grade hardware.
The issue does not stem from intelligence limitations. It comes from hardware constraints. Even high-end systems spend much of their time transferring parameters rather than performing computation, which results in underused processing power and visible lag in output generation.
This limitation has pushed many developers toward smaller or compressed models. Those alternatives improve speed but reduce output quality, which creates a trade-off between performance and capability.
How speculative decoding changes the workflow
Google’s approach avoids that trade-off. Instead of modifying the main model, the company pairs it with a smaller, faster “drafter” model. This drafter predicts multiple tokens ahead of time, while the main model verifies those predictions in parallel.
Google explains the mechanism clearly:
"if the target model agrees with the draft, it accepts the entire sequence in a single forward pass—and even generates an additional token of its own in the process."
This method allows the system to produce several tokens in the time it would normally take to generate one. The main model still validates every output, which ensures that accuracy and reasoning remain unchanged.
The concept itself is not new. Google researchers introduced speculative decoding in earlier work, but recent architectural adjustments have made it practical at scale. The MTP implementation integrates tightly with Gemma 4 models and shares internal memory structures such as the KV cache. This prevents redundant calculations and reduces overall processing time.
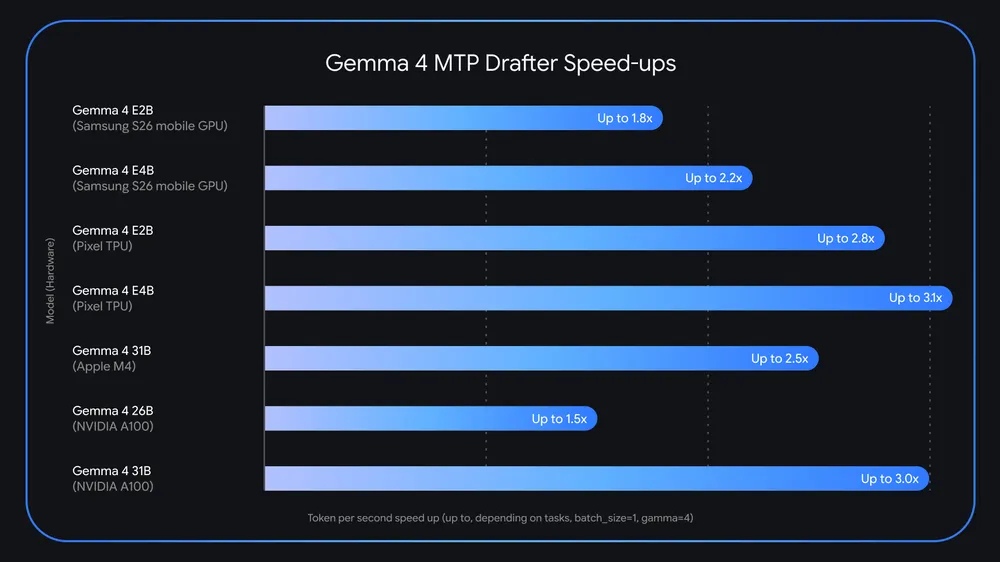
Performance gains across hardware environments
Google reports measurable improvements across multiple hardware setups. A Gemma 4 26B model running on an Nvidia RTX PRO 6000 GPU can achieve roughly double the tokens per second when paired with an MTP drafter. In some scenarios, the increase approaches the advertised threefold improvement.
On Apple Silicon devices, performance also improves when processing multiple requests simultaneously. Batch sizes between four and eight requests can unlock speed gains of around 2.2 times, based on internal testing.
These improvements extend to edge devices as well. Smaller Gemma 4 variants, such as E2B and E4B models, benefit from additional optimizations, including efficient clustering techniques that reduce bottlenecks during token generation.
Practical implications for developers
The update targets developers who rely on low-latency AI systems. Applications such as coding assistants, real-time chat interfaces, and voice-driven tools depend on fast response times to remain usable.
With MTP drafters, developers can run larger models locally without the delays that previously limited their practicality. This enables more complex workflows on personal computers and mobile devices, while also preserving privacy and reducing reliance on cloud infrastructure.
The improvement also affects battery efficiency on edge devices. Faster token generation reduces the time hardware stays active, which can extend device usage in mobile scenarios.
Availability and ecosystem support
The MTP drafters are available under the same Apache 2.0 open-source license as the Gemma 4 models. Developers can access them through platforms such as Hugging Face, Kaggle, and Ollama. The models integrate with widely used frameworks, including Transformers, MLX, vLLM, and SGLang.
Google has also released technical documentation that explains the underlying architecture, including KV cache sharing and embedding optimizations. This allows developers to understand and adapt the system for their own use cases.
Efficiency becomes the new competitive edge
The release reflects a broader shift in the AI industry. Performance improvements no longer depend solely on larger models or increased compute power. Efficiency gains now play a central role in determining how and where AI systems can operate.
Speculative decoding does not replace existing architectures. It enhances them. By focusing on execution speed rather than model redesign, Google positions Gemma 4 as a more practical option for real-world deployment across both local and distributed environments.

Disclaimer: All materials on this site are for informational purposes only. None of the material should be interpreted as investment advice. Please note that, despite the nature of much of the material created and hosted on this website, HODL FM operates as a media and informational platform, not a provider of financial advisory services. The opinions of authors and other contributors are their own and should not be taken as financial advice. If you require advice, HODL FM strongly recommends contacting a qualified industry professional.


